ChapsVision CyberGov, la branche cyber du groupe ChapsVision.
Nous construisons une solution souveraine de cyber intelligence et de cybersécurité, dédiée aux marchés de la défense, du renseignement et de la sécurité.
Téléchargez notre dernier Livre Blanc : La fraude, un fléau aux mille visages
ChapsVision CyberGov a vu le jour car aucun acteur souverain n’était jusqu’ici capable de répondre de manière satisfaisante au besoin de créer de la valeur à partir de la donnée pour servir des cas d’usage spécifiques à la cyber intelligence et la cybersécurité.
ChapsVision CyberGov édite un système d’exploitation de la donnée à la fois ambitieux et souverain qui répond à ce besoin.
La puissance de la data et de l'innovation, au service de l'investigation numérique
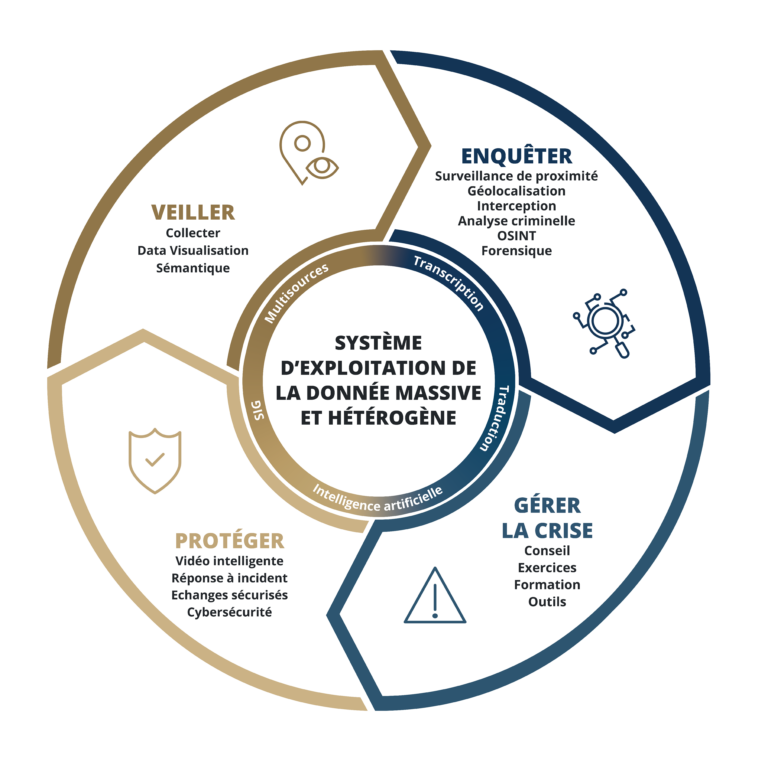
Système d'Exploitation de la data
Pour répondre à un besoin fort des organisations de capitaliser sur toute l’information disponible afin de la rendre facilement exploitable.
Face à une criminalité à la pointe des technologies, les forces de sécurité intérieure nécessitent de disposer du meilleur des outils et application répondant chaque étape des enquêteurs et de leurs missions.
Lorsqu’une crise survient, l’urgence et le stress font leur apparition à tous les niveaux. Pour éviter les erreurs de décision et de communication, faites-vous accompagner par les experts de la gestion de crise à 360°.
Détecter les informations clefs dans les flux de données fait partie des enjeux stratégiques des Etats et des entreprises. Retrouvez le meilleur de l’Intelligence Economique et Stratégique pour comprendre et prendre les bonnes décisions.
La sécurisation tant physique que virtuelle de vos biens et systèmes d’informations sensibles, fait face à de nombreuses menaces. Notre réponse logicielle et servicielle permet de diminuer largement votre exposition aux risques de sûreté et de cybersécurité.
Pour répondre à un besoin fort des organisations de capitaliser sur toute l’information disponible afin de la rendre facilement exploitable.
Face à une criminalité à la pointe des technologies, les forces de sécurité intérieure nécessitent de disposer du meilleur des outils et application répondant chaque étape des enquêteurs et de leurs missions.
Lorsqu’une crise survient, l’urgence et le stress font leur apparition à tous les niveaux. Pour éviter les erreurs de décision et de communication, faites-vous accompagner par les experts de la gestion de crise à 360°.
Détecter les informations clefs dans les flux de données fait partie des enjeux stratégiques des Etats et des entreprises. Retrouvez le meilleur de l’Intelligence Economique et Stratégique pour comprendre et prendre les bonnes décisions.
La sécurisation tant physique que virtuelle de vos biens et systèmes d’informations sensibles, fait face à de nombreuses menaces. Notre réponse logicielle et servicielle permet de diminuer largement votre exposition aux risques de sûreté et de cybersécurité.